


 当前位置:
当前位置:基于定点DSP的MP3音频编码算法研究及实现
[10-10 20:38:44] 来源:http://www.88dzw.com 电子制作 阅读:8623次
文章摘要:寻找快速算法的关键就是这最后一步。将系数设为数组:可以发现该数组具有如下的对称性:所以合并系数相等或相反的项,(1)式变成: 可见用(5)式代替(1)式可以减少一半的乘法运算。又发现(5)式和标准的IDCT非常相似,可以将Lee提出的快速IDCT算法稍加改动推导(5)式的快速算法。所以又将32点变换分解成以下的两个16点变换:直接计算(1)式需要64×32次乘法和63×32次加法,采用快速算法需16×16×2+16×2次乘法和15×16×2+16×2+31+15次加法,运算量为原来的1/4,而且数据表格所占用
基于定点DSP的MP3音频编码算法研究及实现,标签:电子小制作,http://www.88dzw.com寻找快速算法的关键就是这最后一步。将系数设为数组:

可以发现该数组具有如下的对称性:

所以合并系数相等或相反的项,(1)式变成:
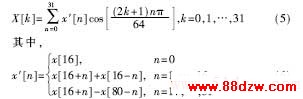
可见用(5)式代替(1)式可以减少一半的乘法运算。又发现(5)式和标准的IDCT非常相似,可以将Lee提出的快速IDCT算法稍加改动推导(5)式的快速算法。所以又将32点变换分解成以下的两个16点变换:


直接计算(1)式需要64×32次乘法和63×32次加法,采用快速算法需16×16×2+16×2次乘法和15×16×2+16×2+31+15次加法,运算量为原来的1/4,而且数据表格所占用的存储空间也减少为原来的1/8左右。
2.2心理声学模型的简化
根据试验观察发现每帧的掩蔽阈值曲线大致相同,所以考虑采用静态声学心理模型,具体做法是:首先对某一具有代表性的音频帧,根据心理声学模型计算出掩蔽阈值曲线,在压缩其它音频源时,不再计算每帧的心理声学模型,而是认为每帧信号与上述被分析过的代表帧具有相同的掩蔽特性。这样,虽然不是很准确,但通常情况下,误差不会太大,不易被人耳察觉,省去心理声学模型所需的巨大运算量和存储空间。实践证明编码效果令人满意,而且对于要求不是很高的应用场合,可以认为掩蔽阈值是频率的常数函数,每个频带采用相同的量化阶,也听不出声音质量的明显下降。
2.3量化编码迭代循环的简化
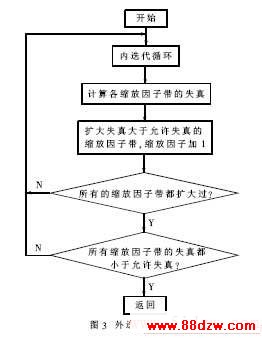
量化编码迭代是两重循环过程,图3是外迭代循环流图,迭代的目的是在可用比特数的限制之内,以各频带的掩蔽值为依据,确定全局增益(体现了全局量化阶)和各频带的缩放因子(体现了局部量化阶)。内循环逐步增加量化器步长,即全局增益,直到MDCT系数量化后可被可用比特进行霍夫曼编码,即通过增加全局量化阶以降低编码比特数;外循环依据掩蔽阈值检测各缩放因子带的失真,若超过允许失真,则扩大该带的MDCT系数,即增大该带的缩放因子,以降低局部失真;最后一次迭代的结果作为最终的霍夫曼码。每一次循环都要用当前的量化阶量化并霍夫曼编码一次,运算量相当大。从外循环可以看出掩蔽阈值最终决定缩放因子,为了能省去外迭代循环,将代表帧的缩放因子作成表格,供每帧采用。
由于上述三个模块是最主要并且运算量最大的模块,通过对它们的简化和优化,程序的大小和运算量可得到极大的减少。
《基于定点DSP的MP3音频编码算法研究及实现》相关文章
- › 基于定点DSP的MP3音频编码算法研究及实现
- 在百度中搜索相关文章:基于定点DSP的MP3音频编码算法研究及实现
- 在谷歌中搜索相关文章:基于定点DSP的MP3音频编码算法研究及实现
- 在soso中搜索相关文章:基于定点DSP的MP3音频编码算法研究及实现
- 在搜狗中搜索相关文章:基于定点DSP的MP3音频编码算法研究及实现