


 当前位置:
当前位置:基于网络处理器的可编程路由器技术研究
[09-12 18:33:21] 来源:http://www.88dzw.com EDA/PLD 阅读:8692次
文章摘要:总之,网络处理器技术是网络发展的趋向,它不仅可以减少开发商的开发成本,缩短开发 时间,加快产品升级换代的能力,同时也保护用户的利益,减少用户在网络新功能需要的投资 和升级换代的费用,所以无论在技术上还是在经济上都具有重要意义。3 IXP1200 网络处理器架构 IXP1200 由六个可编程的微引擎和一个协调系统行为的工作在200MHz 的StrongARM 内 核组成。每个微引擎有四个硬件线程,在IXP1200 芯片上一共有24 个线程。除了微引擎, IXP1200 还用一些别的特殊的硬件设备来辅助进行包处理。 微引擎和StrongARM 还共享有 一个可编程的HASH 引擎和专门的队列,IX
基于网络处理器的可编程路由器技术研究,标签:eda技术,eda技术实用教程,http://www.88dzw.com总之,网络处理器技术是网络发展的趋向,它不仅可以减少开发商的开发成本,缩短开发 时间,加快产品升级换代的能力,同时也保护用户的利益,减少用户在网络新功能需要的投资 和升级换代的费用,所以无论在技术上还是在经济上都具有重要意义。
3 IXP1200 网络处理器架构 IXP1200 由六个可编程的微引擎和一个协调系统行为的工作在200MHz 的StrongARM 内 核组成。每个微引擎有四个硬件线程,在IXP1200 芯片上一共有24 个线程。除了微引擎, IXP1200 还用一些别的特殊的硬件设备来辅助进行包处理。 微引擎和StrongARM 还共享有 一个可编程的HASH 引擎和专门的队列,IXP1200 网络处理器的架构图如图1 所示。
下面我们将对 IXP1200 中的微引擎和StrongARM 做一个详细的介绍。微引擎有一个特 别适用于处理网络数据的指令集。微引擎除了可以在单个指令里执行位、字节、和长字操作外,还有带有移位和循环移位的算术和逻辑操作。但是微引擎没有整数乘或除、也没有浮点 数操作。微引擎的乘法是通过反复进行加运算来完成的。在微引擎中每个指令占用一个长字 (32 位)的存储空间。每个微引擎有一个独立的可容纳1024 条指令的4KB 的指令存储器。 在微引擎开始运行之前,StrongARM 内核上的代码负责给这个指令存储器装入代码。一旦微 引擎运行时,指令以一个五阶段的流水线来运行,并且当流水线充满时,平均只需用一个周 期去执行一条指令。当指令阻塞在存储器或设备存取操作完成时,或当跳转指令迫使在流水 线中的某些指令退出执行,平均的指令执行时间就会长于一个周期。
在IXP1200 系列处理器上的StrongARM 内核是基于INTEL 的SA-1 内核。这个内核实现 由ARM 公司定义的32 位的ARM V4 架构。StrongARM 内核在计算能力和功耗上是一种折衷的 选择。编程StrongARM 内核和编程嵌入式通用处理器没有太大的差别。
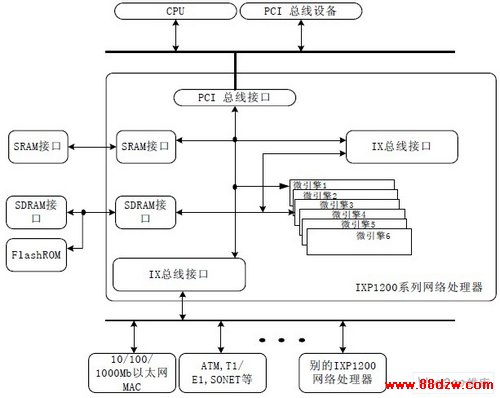
图 1:IXP1200 网络处理器架构
在一个微引擎的线程之间以轮转方式实行非抢占式的硬件线程仲裁交换,而且只有准备 好运行的线程才能够被交换到运行状态。调度器保存有已准备运行的线程号,当有线程准备 放弃微引擎的控制权时,调度器在微引擎中以线程标志号的顺序次序搜寻一个准备运行的线 程。对于有抢占式调度的操作系统,开发者不能控制也不能预测什么时候为了让另一个代码 块运行而中断一个指定的代码块。而在微引擎中,在另一个代码被运行之前,当前代码必须 明确放弃微引擎的控制权。这使得开发者可以控制代码的实际运行情况。因为代码访问存储 器是一个会消耗数十个周期的操作。所以一般情况下,当线程等待存储器或别的硬件操作时, 线程会自动放弃对微引擎的控制权。当线程等待存储器操作完成时,线程可以交换出去并允 许别的线程去运行。这种策略最大化了微引擎正在执行的工作量。非抢占式线程调度使微引 擎能够异步的处理存储器。一个微引擎能明确选择释放微引擎的控制权,它也能选择不释放 控制权,等待一个存储器操作。如,一个微引擎线程发出一个存储器读请求操作,然后又继 续执行其它指令。存储器读请求操作的完成信号然后能被异步的反馈给微引擎线程。异步存 储器读操作是微引擎和大多数通用处理器的一个重要的区分。
4、基于网络处理器的路由器
在网络发展初期,网络传输的速率较低,没有必要用专用的处理器处理分组,用原有的通 用处理器就可以满足分组转发的速率要求,但随着网络速度的提高,通用处理器已经不能适 应网络高速发展的需要。因此,需要想办法提高路由器的性能,利用硬件处理分组的转发是很 自然能想到的方法,所以就出现了基于ASIC 的路由器。基于ASIC 的路由器仍是当前提高网 络设备速率的主流,它的最大缺点是缺乏灵活性,一旦把特性嵌入到硅片上,就很难来增加新 的特性和改善性能。设计和制造一个复杂的ASIC 要花费12 个月到两年的时间,这对路由器 厂商来说,需要在发展周期中提前预测出市场可能最需要的特性和协议。它以失去灵活性和 快速响应市场的能力作为代价来获取速度。随着网络应用领域的迅速扩大,新的特性(虚拟局 域网VLAN、虚拟专用网VPN 等)和用户的新需求(多媒体、视频点播、视频会议等)不断出现 和变化,这样,由于ASIC 固有的不灵活性,导致厂商不能快速地对用户要求的功能做出响应, 使厂商失去了快速响应市场的能力,于是人们在研究一种既能满足性能要求又能满足灵活的 处理器,这就是网络处理器。除此之外,ASIC 还有引脚太多(200~400 个引脚),价格昂贵等缺 点。另外,局域网流量的分布变化促进了网络处理器的发展。由Internet 规模和应用的发展, 以往大部分的通信限于局域网内部,而现在有相当一部分的信息是和局域网外部网络进行交 换的。而且这种趋势还会不断地增加,这使得分组将传输在更复杂的,多种多样的网络体系上, 相应地,安全问题(如加密、授权与鉴定、高级监控和入侵监测等)也成为重点考虑的对象, 为了提供不同服务质量(如IP 广播、高级的服务质量Qos),网络控制也将复杂得多,所有这 些要求路由器变得更加智能,同时要以线速处理7 层网络协议(OSI)的高层内容,以满足用户 要求的不同服务,由于ASIC 是用硬件来实现这些性能的,不能进行编程,所以就不能快速满 足用户的这些新要求,于是,基于网络处理器的路由器应运而生。
- 上一篇:基于FPGA的可复用通信接口设计
《基于网络处理器的可编程路由器技术研究》相关文章
- › 基于网络的智能精密压力传感器原理与应用
- › 基于网络处理器的可编程路由器技术研究
- 在百度中搜索相关文章:基于网络处理器的可编程路由器技术研究
- 在谷歌中搜索相关文章:基于网络处理器的可编程路由器技术研究
- 在soso中搜索相关文章:基于网络处理器的可编程路由器技术研究
- 在搜狗中搜索相关文章:基于网络处理器的可编程路由器技术研究