


 当前位置:
当前位置:基于802.16d的定时同步算法改进及FPGA实现
[09-12 18:26:39] 来源:http://www.88dzw.com EDA/PLD 阅读:8500次
文章摘要:式中,c(n)为短训练符号在本地的复制样本,N为短训练符号的样值点数。当已知的训练序列和接收训练序列恰好对齐时,也会产生一个峰值,其仿真曲线如图1中的实曲线所示。该算法的缺点是易受频偏的影响。根据以上分析,并从算法性能上考虑,若采用延迟自相关法,帧到达时会出现一个峰值平台,该方法并不能确定帧到达的准确时刻;而采用与本地序列互相关算法又容易受到频偏的影响而导致定时偏差。3 算法改进针对上述算法的不足,可对其加以改进,以保证同时具有良好的性能和硬件实现的可行性。改进算法是将两种算法结合起来进行联合估计,首先确定一个帧到达的大致平台,再在这个平台内找到互相关峰值,如果各个峰值间隔相等,那么可根据最后
基于802.16d的定时同步算法改进及FPGA实现,标签:eda技术,eda技术实用教程,http://www.88dzw.com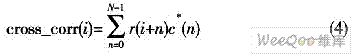
式中,c(n)为短训练符号在本地的复制样本,N为短训练符号的样值点数。当已知的训练序列和接收训练序列恰好对齐时,也会产生一个峰值,其仿真曲线如图1中的实曲线所示。该算法的缺点是易受频偏的影响。
根据以上分析,并从算法性能上考虑,若采用延迟自相关法,帧到达时会出现一个峰值平台,该方法并不能确定帧到达的准确时刻;而采用与本地序列互相关算法又容易受到频偏的影响而导致定时偏差。
3 算法改进
针对上述算法的不足,可对其加以改进,以保证同时具有良好的性能和硬件实现的可行性。改进算法是将两种算法结合起来进行联合估计,首先确定一个帧到达的大致平台,再在这个平台内找到互相关峰值,如果各个峰值间隔相等,那么可根据最后一个峰值来判断下一个符号的开始。这种联合估计的办法在软件仿真时具有良好的性能,但若要在硬件上实现则比较困难。因为在延时自相关算法中,计算M(n)的值虽然可采用迭代算法,每次计算只需1次复数运算和若干加法运算;但在自相关计算中,假设接收信号被定点化为16位整数,那么计算一次自相关的值需要16位数据的64次复数乘法,显然,所需要的硬件资源开销非常大,而且会影响系统的运行速度。这在硬件上,因资源消耗太大而无法实现。为了兼顾算法的估计精度和实现的复杂性,有必要将算法做进一步改进。即对接收数据进行二阶量化以得到d[n]=Q[r(n)],其中Q表示复数量化器,见下式:
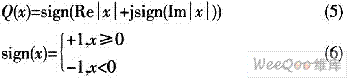
利用这种改进的自相关算法和延时自相关算法进行联合估计的仿真曲线如图2所示。
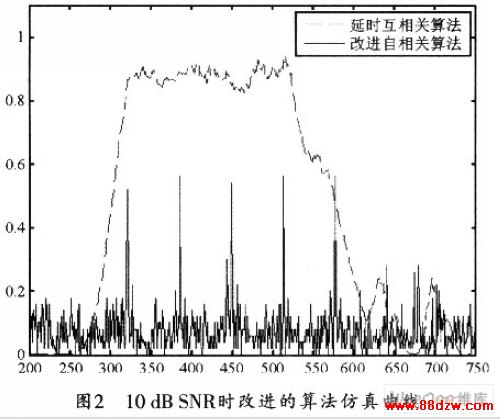
将图1和图2进行对比可知,这种对接收数据二阶量化的方法会损耗算法的性能,但是,由于帧的大致位置已被限制在一定范围之内,因此,只需根据峰值就可以确定下一个OFDM符号的准确位置。这种方法既能保证估计精度,又能满足硬件资源利用率的要求。
4 基于FPGA的实现
4.1 自相关延时模块的FPGA实现
为了进一步简化运算,也可以不进行算法中的归一化运算,而直接计算R(n)的值,并将公式简化为:
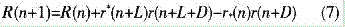
图3所示是自相关延时模块的硬件组成结构。它主要由FIFO延时单元、复数运算器、加法器、取模模块组成。其中复数乘法器可直接使用IP核来实现,这比直接使用四个实数乘法器和两个加法器更节省资源。
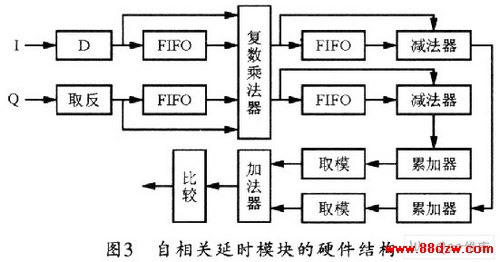
将接收端经过下变频的I路和Q路数据分为两路送入模块,I路比Q路数据应多延时一个时钟周期,这是为了和Q路数据保持相同的时延,此后再进入FIFO经过64个时钟周期的延时。Q路数据首先进行取相反数运算。这是因为复数共轭运算相当于先取相反数再做复数乘法。把相减的结果送入FIFO进行延时,并将送入系统的复数与做减法和延时64个时钟周期的复数进行复数乘法运算。由于两路数据都是16位定点化整数,经过运算后会成为33位,为了节省资源,可将所得结果的高5位和低12位截去,而这并不会影响运算的精度。经过复数乘法运算的实部和虚部再分别经过64个时钟周期的FIFO延时,并将延时前后的数据做减法运算,然后对计算的结果做累加运算。累加器输出的结果经过取模模块后,即可得到实部和虚部的绝对值,然后将两部分结果相加,再将相加结果与门限值比较,超过门限则将标志位置高。但应注意门限值的选取会影响帧检测的范围,由于采用的是联合检测方法,应适当扩大门限范围,本设计设定的门限值为峰值的1/4。
《基于802.16d的定时同步算法改进及FPGA实现》相关文章
- › 基于8051的微控制器在系统编程
- › 基于802.16d的定时同步算法改进及FPGA实现
- › 基于8051单片机的频率测量技术
- › 基于80C552单片机的多芯片同步复位电路
- › 基于80C166单片机PEC服务的PROFIBUS-FDL从站协议实现
- › 基于80C196MC的步进电机恒转矩
- 在百度中搜索相关文章:基于802.16d的定时同步算法改进及FPGA实现
- 在谷歌中搜索相关文章:基于802.16d的定时同步算法改进及FPGA实现
- 在soso中搜索相关文章:基于802.16d的定时同步算法改进及FPGA实现
- 在搜狗中搜索相关文章:基于802.16d的定时同步算法改进及FPGA实现