


 当前位置:
当前位置:基于FPGA的级联结构FFT处理器的优化设计
[09-12 18:26:43] 来源:http://www.88dzw.com EDA/PLD 阅读:8408次
文章摘要:采用并行流水结构实现的基-16运算核,一个数据时钟可处理16个数据。而每次蝶形运算在一个数据时钟内只需要计算出一个结果,这将造成资源浪费。因此,采用级联结构实现的基-16蝶形运算核,用两个基-4蝶形运算核分别复用4次来实现每一级中的四个蝶行运算,中间用一个串行出入/输出的寄存器进行连接,其结构框图如图3所示。2.2 基-4蝶形运算核基-4蝶形运算核的结构如图4所示,其中加减模块为两级流水结构,一次可以计算4个数据。蝶形运算的四个串行输入数据经串/并转换器转换为四路并行数据,进入加减运算单元。计算出的4个并行结果进入并/串转换器后,串行输入复数乘法器和旋转因子相乘然后输出结果。因为图1中最后一级
基于FPGA的级联结构FFT处理器的优化设计,标签:eda技术,eda技术实用教程,http://www.88dzw.com 采用并行流水结构实现的基-16运算核,一个数据时钟可处理16个数据。而每次蝶形运算在一个数据时钟内只需要计算出一个结果,这将造成资源浪费。因此,采用级联结构实现的基-16蝶形运算核,用两个基-4蝶形运算核分别复用4次来实现每一级中的四个蝶行运算,中间用一个串行出入/输出的寄存器进行连接,其结构框图如图3所示。
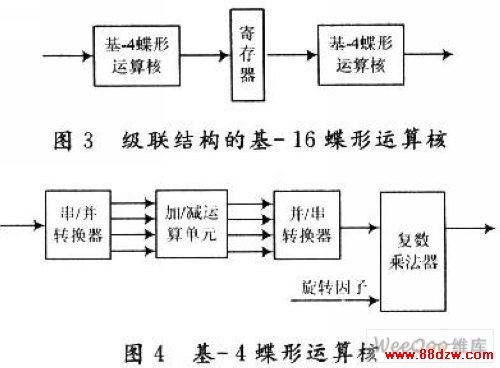
2.2 基-4蝶形运算核
基-4蝶形运算核的结构如图4所示,其中加减模块为两级流水结构,一次可以计算4个数据。蝶形运算的四个串行输入数据经串/并转换器转换为四路并行数据,进入加减运算单元。计算出的4个并行结果进入并/串转换器后,串行输入复数乘法器和旋转因子相乘然后输出结果。因为图1中最后一级的数据只需要进行加减运算不需要再乘以旋转因子,所以图1中的基-4蝶形运算核是没有复数乘法器的,数据从并/串转换器中直接输出给缓冲存储器。
2.3 复数乘法器
虽然现在的高端产中已经集成了可以完成乘法的DSP资源,但也是有限的。因此高效复数乘法器的设计对该设计来讲仍然非常的重要。复数乘法的标准式如下:
R+jI=(A+jB)×(C+jD)=(AC-BD)+j(AD+BC)
式中:A,B分别为输人数据的实部和虚部,C和D分别为旋转因子的实部和虚部。按照这种标准表达式,执行一次复数乘法需要进行4次实数乘法,2次实数加法和2次实数减法。将上述公式重新整理为:R=(C-D)・B+C(A-B),I=(C-D)A-C(A-B)优化后的复数乘法器需要进行3次实数乘法,2次实数加法和3次实数减法,相比传统结构多了一个减法器,少了一个乘法器。在FPGA中,加减法模块所占用的相对裸片面积要小于相同位数的乘法器模块。这样的优化还是很有价值的,在FFT吞吐量不变的情况下,可减少25%的乘法器使用量,在乘法器数量一定的情况下可高FFT吞吐量。
3 存储器单元
传统的级联结构的FFT处理器的缓冲存储器都是采用乒乓结构,基本思想就是用两块相同的RAM交替读出或写入数据。即其中一块RAM在写入数据时,另一块RAM用于读出数据。当用于写入数据的RAM写满时交换读写功能。将乒乓结构中RAM的内部存储单元地址用二进制数a9a8a7a6a5a4a3a2a1a0表示。以写满其中以块RAM为一个周期,用一个二进制计数器m9m8m7m6m5m4m3m2m1m0生成的顺序写入,混序读取的乒乓结构RAM的操作地址如表1所示。

表1中第一,二,四块存储器的写操作地址和读操作地址是可以互换的,也就是将数据混序写入,顺序读取。因此,根据这个规律采用一块可同时读写的双端口RAM来实现第一,二,四块存储器。其基本思想就是对同一个地址进行读和写。以用一块双端口RAM实现第一块存储器的为例,在第一个周期内双端口RAM按照地址m9msm7m6m5mdm3m2m1m0进行写操作,即数据是按照自然顺序储存的。在第二个周期按照地址m0m1m2m3m4m5m6m7msm9同时进行读写操作,读出的数据按照倒位序排列,写入的数据按照倒位序储存的。 在第三个周期按照地址m9msm7m6m5m4m3m2m1m0同时进行读写操作,读出的数据按照倒位序排列,写入的数据是按照自然顺序储存的。依次类推下去,读出的数据都是按照倒位序排列。同样第二块和第四块存储器的存储地址也具有这样类似的循环规律。因此只有第三块存储器需要用乒乓结构的RAM实现,与传统所有存储器都用乒乓结构RAM实现相比,节省了3/8的存储单元。设计中用Matlab软件直接生成旋转因子,并将其转化为16位有符号定点数写入MIF文件。然后用ROM直接调用MIF文件,将旋转因子预置在ROM中。
4 仿真结果
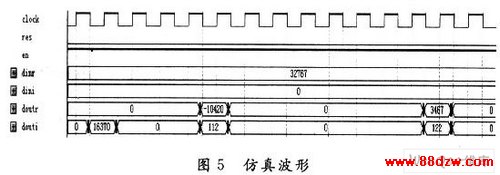
选用Altera公司生产的Cyclone Ⅱ的EP2C35F484C7芯片上进行验证,在QuartyusⅡ7.2软件中进行编译和仿真。通过对高基核的优化处理,该设计对逻辑单元消耗量和传统用基-4算法实现相近,仅为4 399,但由于本文采用了高基低基组合的混合基算法,在处理1 024点的离散数列时,处理器所分的级数仅为3级,相对传统的低基数算法,其实现减少了对缓冲存储器块数的需求;并通过对缓冲存储器的优化设计,又比全部用乒乓结构RAM实现的传统方法节省了3/8的存储单元,因此占用的存储资源仅为154 048 b。仿真波形如图5所示,该仿真结果和Matlab计算结果基本一致,存在一定的误差是由于有限字长效应引起的。
5 结 语
在100 MHz的时钟下工作,完成一次1 024点的FFT从输入初始数据到运算结果完全输出仅需要54.48μs,且连续运算时,处理一组1 024点FFT的时间仅为10.24 μs,达到了高速信号处理的要求。
《基于FPGA的级联结构FFT处理器的优化设计》相关文章
- › 基于FPGA的单片彩色LCD投影机设计
- › 256级灰度LED点阵屏显示原理及基于FPGA的电路设计
- › 基于FPGA的LCD%26amp;VGA控制器设计
- › 基于FPGA的信道化接收机
- › 基于FPGA和SMT387的SAR数据采集与存储系统
- › 基于FPGA的栈空间管理器的研究和设计
- 在百度中搜索相关文章:基于FPGA的级联结构FFT处理器的优化设计
- 在谷歌中搜索相关文章:基于FPGA的级联结构FFT处理器的优化设计
- 在soso中搜索相关文章:基于FPGA的级联结构FFT处理器的优化设计
- 在搜狗中搜索相关文章:基于FPGA的级联结构FFT处理器的优化设计